Communication is, ultimately, about sending and receiving messages. People communicate using messages, so do devices/hardware and applications/software.
An application is a dead beetle unless it's alive when running. A process is a running instance of an application. (For our purposes, I shall be using the words application and process interchangeably.) For processes to be able to communicate, there needs to be a point through which processes can reach to one another. Similar to an open door through which somebody can come and ask/inform/demand something.
This endpoint is called a socket, which is bound to (associated with) a port (a software construct, whose purpose is to uniquely identify different applications running on a single computer). The Operating System provides an API (Application Programming interface) - an established way, processes can use to manipulate the sockets, ie use them for communication.
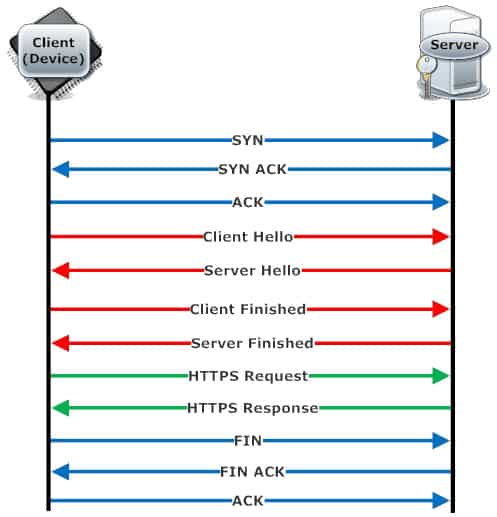
There are two types of sockets; one used for local inter-process communication within an Operating System/a single machine (Unix domain socket); the other is Network socket, used for communication of applications distributed over a network. Network sockets are particularly of interest to us. They are uniquely described by :
Processes running on the same machine can communicate through:
Processes running on distributed machines:
running on a remote system. RPC protocol can use either
XML or JSON format for data transfer and uses HTTP as its
data transport mechanism (lets applications use HTTP to
make connection, but uses its own RPC protocol to interpret
the request and the response). A request is sent to a
server/application implementing the XML-RPC protocol.
a prescribed way of implementation. REST uses the
HTTP design instead of inventing a new mechanism.
In the RESTful world, all revolves around resources (URI/URL),
and their recovery and changes : read, created, updated, deleted (CRUD).
RPC:
MQ protocols provide a common standard for applications, that want to use this type of communication. There are different messaging types/design patterns, some of which need or can take advantage of a middle man (called middleware), that has full responsibility for queues: creates them, routes messages to them, handles failures, sends messages to requesters and more.
An application is a dead beetle unless it's alive when running. A process is a running instance of an application. (For our purposes, I shall be using the words application and process interchangeably.) For processes to be able to communicate, there needs to be a point through which processes can reach to one another. Similar to an open door through which somebody can come and ask/inform/demand something.
This endpoint is called a socket, which is bound to (associated with) a port (a software construct, whose purpose is to uniquely identify different applications running on a single computer). The Operating System provides an API (Application Programming interface) - an established way, processes can use to manipulate the sockets, ie use them for communication.
There are two types of sockets; one used for local inter-process communication within an Operating System/a single machine (Unix domain socket); the other is Network socket, used for communication of applications distributed over a network. Network sockets are particularly of interest to us. They are uniquely described by :
- a combination of local IP address and a port number
- Protocol (TCP (reliable, connection oriented)/UDP (unreliable, connectionless, faster)
- remote IP address and remote port number (only for established TCP sockets: one local TCP socket can be used by multiple remote TCP clients, each with its own IP address and port)
Processes running on the same machine can communicate through:
- files
- pipes
- signals
- locally shared memory
- local database
Processes running on distributed machines:
- remote database
- memcachedb
- memcached
- web services
- memory queues
File
use CHI;
my $cache = CHI->new( driver => 'BerkeleyDB', root_dir => '/path/to/cache'
Memory based
use CHI; my $cache = CHI->new( driver => 'SharedMem', size => 10 * 1024, shmkey => 'UniqueNamespace', # This namespace will be used by processes
# wanting to communicate. All caches
# (in different processes) with this shmkey
# will be shared
);
Database
Multiple processes access the database to perform read/create/update/delete (CRUD operations). Database engines allow table or row locking to prevent inconsistencies and corruption of data.
memcachedb
Distributed database storage.
memcached
Distributed memory caching. From application's perpective, the same as in-process memory caching. The difference compared to in-process memory caching is, that memcached will decide on which of the memcached servers to store the value and will know from where to retrieve it later.
my $cache = CHI->new( driver => 'Memcached::libmemcached', servers => [ "192.168.1.150:11211",
"192.168.1.150:11212",
"192.168.1.151:11211",
"192.168.1.151:11212",], l1_cache => { driver => 'FastMmap',
root_dir => '/path/to/cache' } );
Web services
- RPC (Remote Procedure Call)
running on a remote system. RPC protocol can use either
XML or JSON format for data transfer and uses HTTP as its
data transport mechanism (lets applications use HTTP to
make connection, but uses its own RPC protocol to interpret
the request and the response). A request is sent to a
server/application implementing the XML-RPC protocol.
- REST (Representational State Transfer)
a prescribed way of implementation. REST uses the
HTTP design instead of inventing a new mechanism.
In the RESTful world, all revolves around resources (URI/URL),
and their recovery and changes : read, created, updated, deleted (CRUD).
Examples of RPC and RESTful requests:
Information is stored about servers in datacentres. A remote application needs to know which servers are currently in use in the US datacentres.RPC:
<?xml version="1.0"?> <methodCall> <methodName>get_active_servers</methodName> <params> <param> <value><country>3</country></value> </param> </params> </methodCall>
REST:
https://hostname/country/3/server/active/1 (sent with HTTP GET method)
Example: RPC implementation using RabbitMQ- SOAP - mentioned for completeness
Message queue (MQ)
Messaging systems are built to asynchronously connect multiple systems, by passing messages between them. (Messaging Anti-Patterns: Part 1).
Message queues are software components providing asynchronous communication between applications. Applications using the concept of memory queues, need to adhere to one of the message queue protocols, ie need to use a common "language" to understand each other. Some of the most common ones are AMQP (Advanced Message Queue Protocol), STOMP (Streaming Text Oriented Message Protocol), MQTT (Message Queue Telemetry Transport), Web Socket Protocol and WAMP (Web Application Messaging Protocol).
Protocols:
AMQP
Main features are reliability and interoperability. Offers a wide
range of features related to messaging, including reliable queuing,
topic-based publish-and-subscribe messaging, flexible routing,
transactions, and security.
STOMP
text-based, does not work with queues and topics, ie does not provide a firm base for interchange
MQTT
provides publish-and-subscribe messaging (no concept of queues despite the
name). It was specially designed for resource-constrained devices and
low bandwidth. MQTT’s strengths are simplicity (offers only five API methods) and a compact binary packet payload. These make it suitable for connecting devices like Arduino to a web service with MQTT etc.
Web Socket
overcomes limitations of HTTP's design based on one-directional communication. Web Socket Protocol is used by applications requiring bidirectional, real-time communication.
WAMP
is a subprotocol, built on top of the Web Socket Protocol. A common protocol for Publish/Subscribe and RPC communication methods (design patterns).
Examples:
RabbitMQ (message broker/middleware, based on AMQP.)
Example: RPC client/server implementation using RabbitMQ
Example: RPC client/server implementation using RabbitMQ



{kind=link}